FlagGems Overview#
About FlagGems#
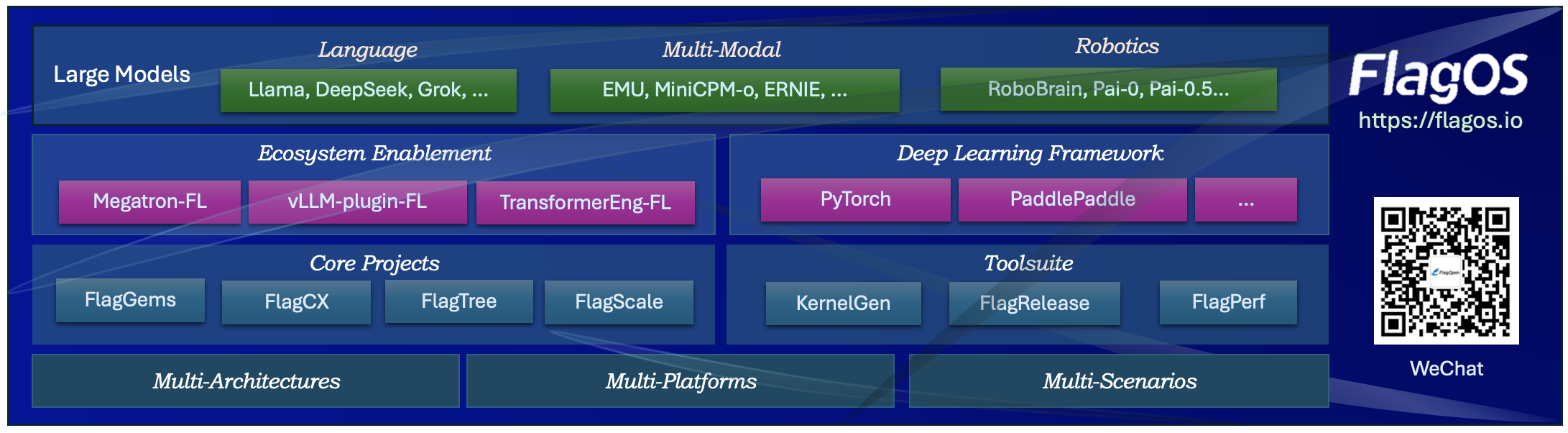
FlagGems is a high-performance general operator library implemented in the Triton language. It aims to provide a suite of kernel functions to accelerate LLM training and inference.
By registering with the ATen backend of PyTorch, FlagGems facilitates a seamless transition, allowing users to switch to the Triton function library without the need to modify their model code.
FlagGems is supported by the OpenAI Triton compiler (for NVIDIA and AMD) and FlagTree compiler for different AI hardware platforms. Users can continue to use the ATen backend as usual while enjoying significant performance enhancement. The Triton language offers benefits in readability, user-friendliness and performance comparable to CUDA. This convenience allows developers to engage in the development of FlagGems with minimal learning effort.
Next step#
- Review features highlighted
- Review platforms supported
- Getting started with FlagGems
- Check the project changelog
- Review the list of operators suppored
Supported models#
- Bert-base-uncased
- Llama-2-7b
- Llava-1.5-7b
Contribution#
If you are interested in contributing to the FlagGems project, please refer to the contributing guide page. Any kind of contributions would be highly appreciated.
Contact us#
If you have any questions about our project, please submit an issue, or contact us through flaggems@baai.ac.cn.
We also created WeChat group for FlagGems. Scan the QR code to join the group chat! To get the first hand message about our updates and new release, or having any questions or ideas, join us now!