Features Overview#
Rich Collection of Operators#
FlagGems features a large collection of PyTorch compatible operators. Refer to operator supported and experimental operators for list of formally supported operators and experimental operators.
Hand-optimized Performance for Selected Operators#
The following chart shows the speedup of FlagGems compared with PyTorch ATen library in eager mode. The speedup is calculated by averaging the speedup on each shape, representing the overall performance of the operator.
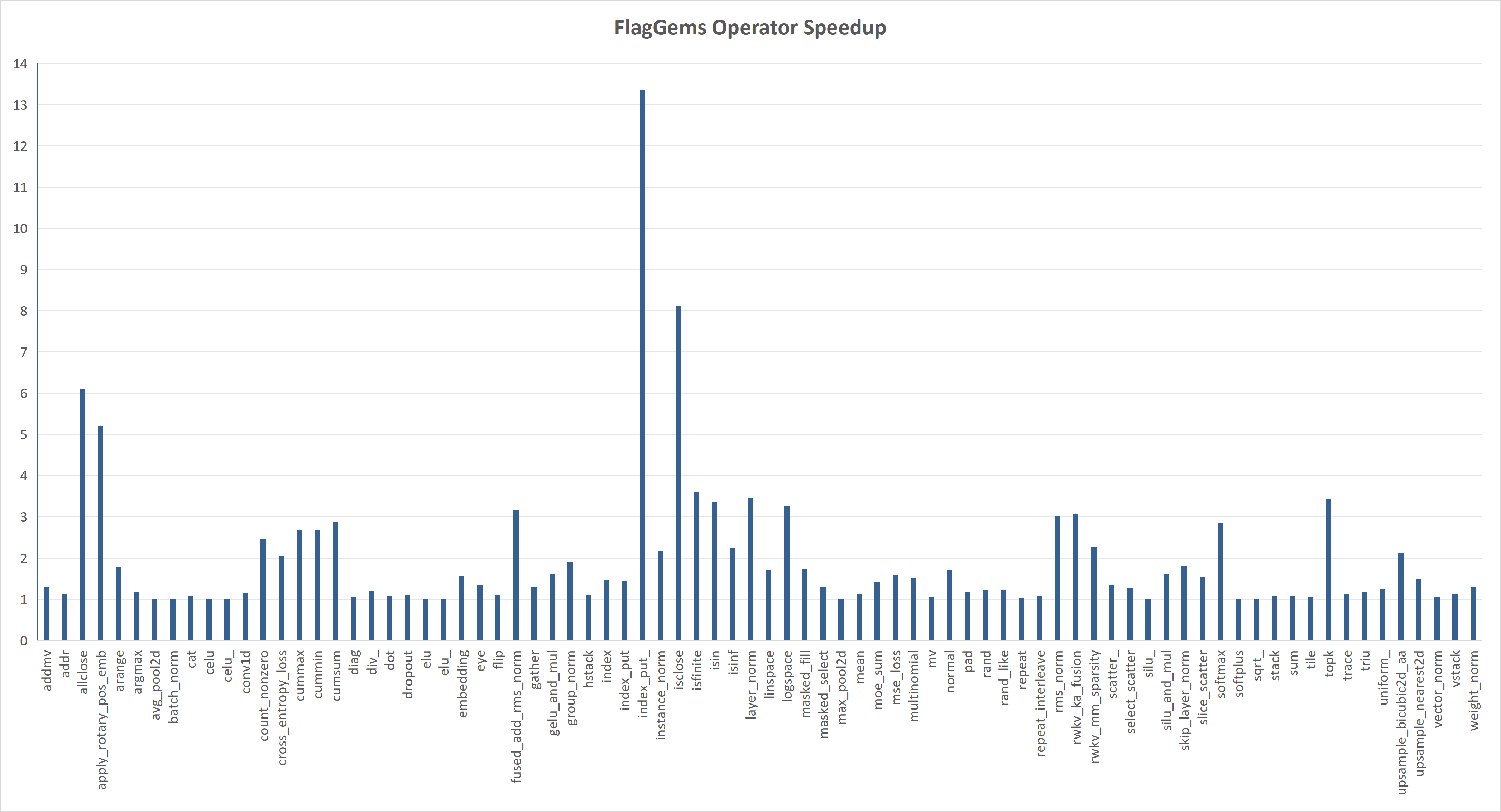
Eager-mode ready, independent of torch.compile#
TODO: contents
Automatic Code Generation#
FlagGems provides an automatic code generation mechanism that enables developers to easily generate both pointwise and fused operators. The auto-generation system supports a variety of requirements, including standard element-wise computations, non-tensor parameters, and specifying output data types. For more details, please refer to the pointwise dynamic documentation.
Function-level kernel dispatching#
FlagGems introduces LibEntry, which independently manages the kernel cache and
bypasses the runtime of Autotuner, Heuristics, and JitFunction.
To use this feature, simply decorate the Triton kernel with LibEntry.
LibEntry also supports direct wrapping of Autotuner, Heuristics, and JitFunction,
preserving full tuning functionality. However, it avoids nested runtime type invocations,
eliminating redundant parameter processing. This means no need for binding or type wrapping,
resulting in a simplified cache key format and reduced unnecessary key computation.
Multi-backend hardware support#
FlagGems supports a wide range of hardware platforms (10+ backends) and has been extensively tested across different hardware configurations. For a comprehensive and up to date list of supported platforms, please check platforms supported.
C++-wrapped operators#
C++ Triton Function Dispatcher#
FlagGems can be installed either as a pure Python package or as a package with C++ extensions. The C++ runtime is designed to address the overhead of the Python runtime and improve end-to-end performance.
There is an ongoing work that implements the Triton function dispatcher in C++ language. Stay tuned.