Performance Benchmarking Overview#
FlagGems operators in general provides better or at least comparable performance
when compared to operators from the native PyTorch library.
We use the triton.testing.do_bench from the Triton project for benchmarking.
The kernel data obtained are shown in the following graph.
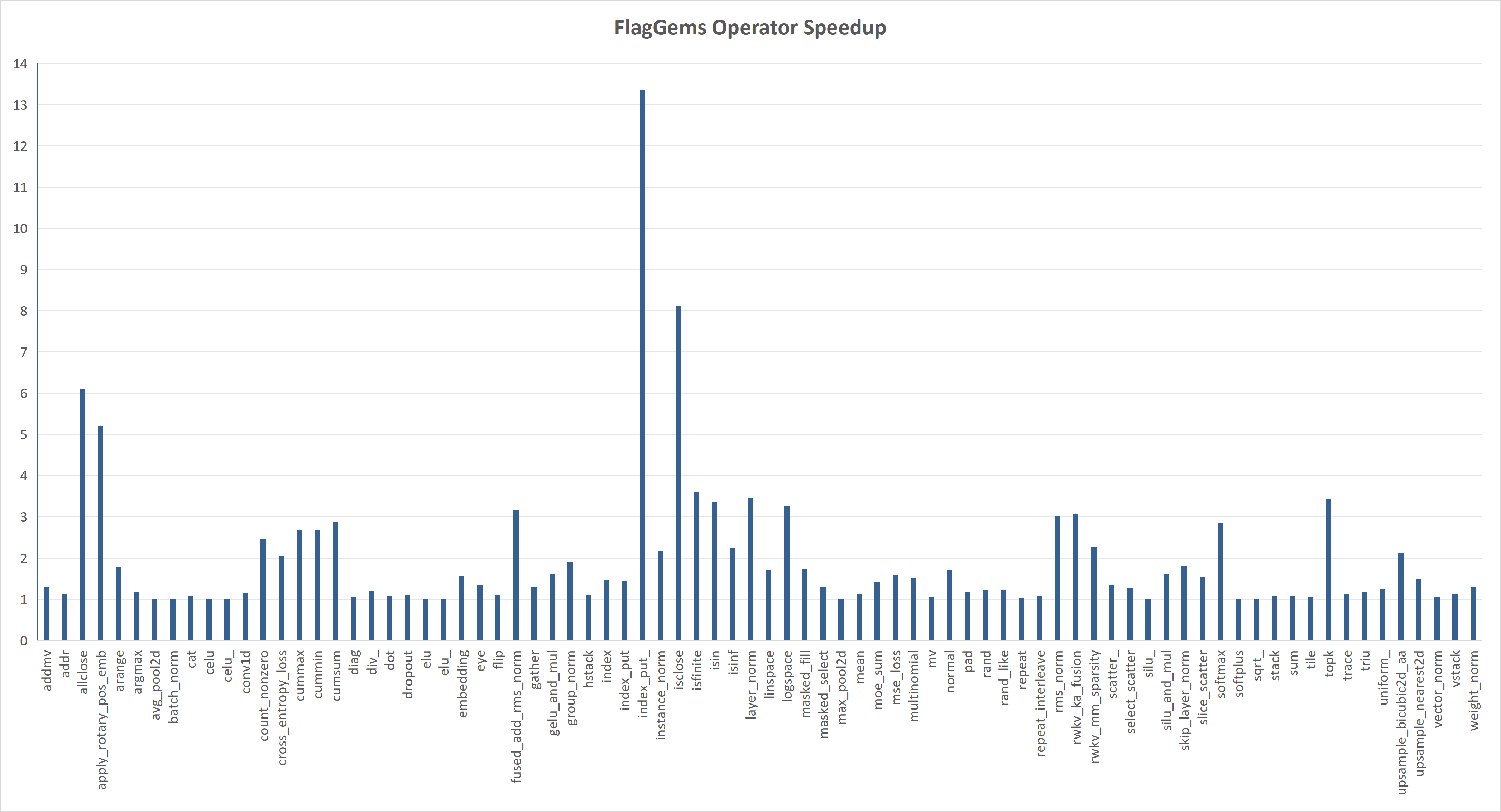
The chart above shows the speedup of FlagGems compared with the PyTorch ATen library in eager mode. The speedup is calculated by averaging the speedup on each shape, representing the overall performance of the operator.
To ensure that the performance of any new operators are within an acceptable range, we require all contributions to the operators' inventory provide performance data. You can benchmark your new operators (and the existing ones) using the benchmark framework in FlagGems.
Check operator benchmark for instructions on benchmark testing your operators.