功能特性概览#
丰富的算子集合#
FlagGems 的一大特性是提供丰富的 PyTorch 兼容算子集合。 参阅支持的算子和 实验性算子 页面了解正式支持的算子集合以及当前处于实验阶段的其他算子。
针对部分算子的选择性手工性能优化#
下面的图表中显示的是 FlagGems 与 PyTorch ATen 算子库在 Eager 模式下的性能比较。 所展示的数据是针对不同数据形状下加速比的平均值,代表了算子的总体性能。
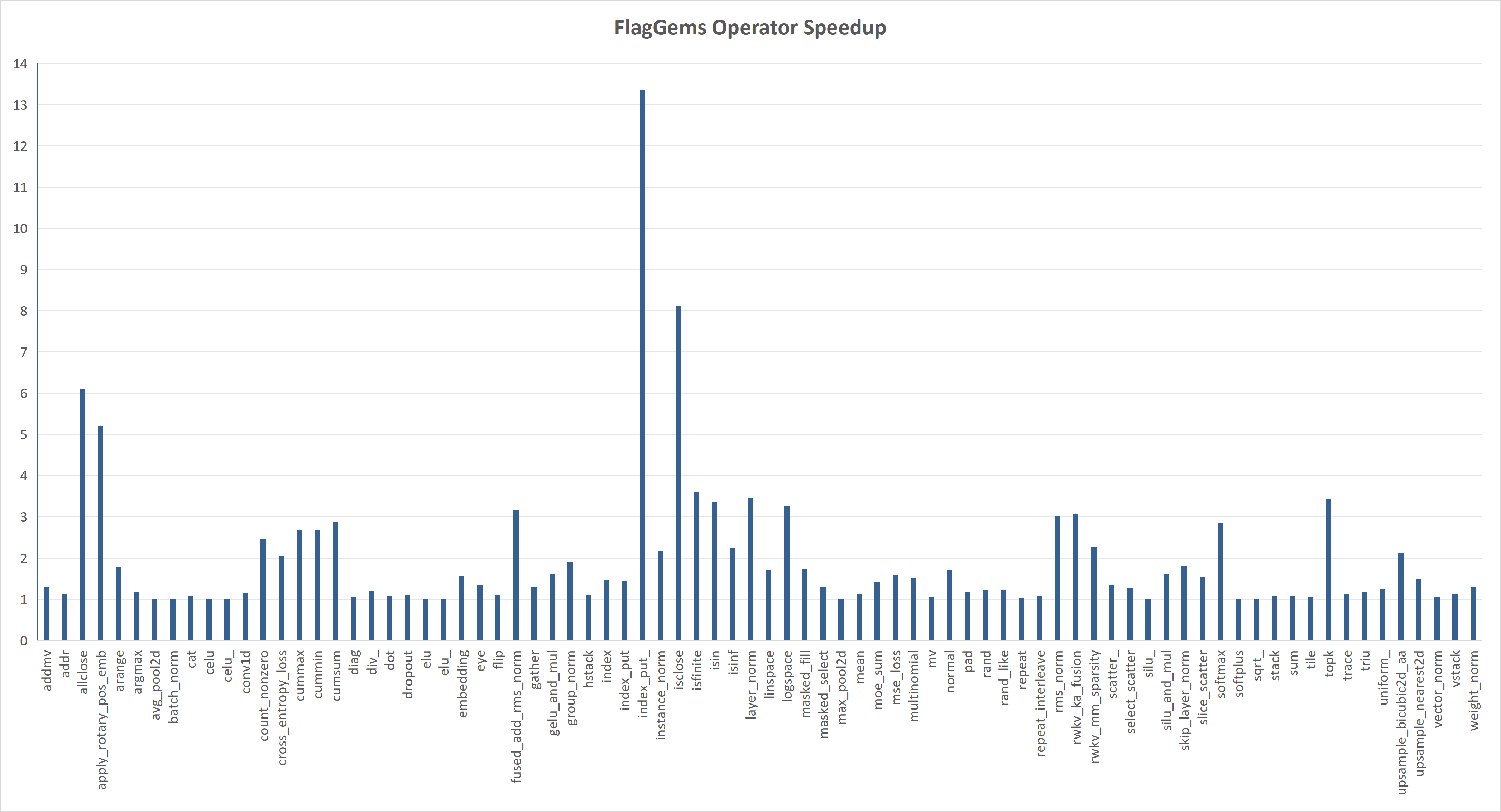
直接进入 Eager 模式,无需 torch.compile#
TODO: 内容待补充。
自动代码生成#
FlagGems 提供一种自动代码生成的机制,方便开发者生成逐点(pointwise) 算子和融合(fused)算子。代码自动生成系统能够满足多种不同的需求, 包括标准的逐元素(element-wise)计算、非张量参数以及设定输出数据类型等等。 参阅逐点动态算子文档以了解更多细节。
函数层级内核派发#
FlagGems 提供 LibEntry 来独立管理对内核的缓存,从而越过 Autotuner、
Heuristics 和 JitFunction 等运行时处理机制。要使用这一特性,
你可以为对应的 Triton 内核添加 libentry 修饰符。
LibEntry 类也支持对 Autotuner、Heuristics 和 JitFunction 的直接封装,
从而完整地保留性能调优能力。不过,LibEntry 能够避免嵌套的运行时类型调用,
消除冗余的参数处理操作。这就意味着,开发者不需要绑定或者封装类型信息,
所使用的将是一种简化的缓存键格式,减少了不必要的键值计算操作。
多种后端硬件支持#
FlagGems 支持很多种硬件平台(后端超过 10 种),并且已经在不同硬件配置环境下通过了大量测测试。 参阅平台支持了解完整的、最新的支持平台列表。
C++ 封装的算子#
FlagGems 可以作为纯 Python 包来安装,也可以附带 C++ 扩展支持特性来安装。 其中的 C++ 运行时被设计用来解决 Python 运行时的性能开销问题, 旨在提高最终系统的端到端性能。
开发团队目前正在尝试用 C++ 语言实现 Triton 的函数派发程序。敬请留意。